How does focal loss help in calibrating deep neural networks?

Paper: Calibrating Deep Neural Networks using Focal Loss
What we want
- Overparameterised classifier deep neural networks trained on the conventional cross-entropy objective are known to be overconfident and thus miscalibrated.
- With these networks being deployed in real-life applications like autonomous driving and medical diagnosis, it is imperative for them to predict with calibrated confidence estimates.
- Ideally, we want a model which is confident on its correct predictions, produces calibrated probability estimates and also achieves state-of-the-art test set accuracy.
What we do
- We explore an alternative loss function, focal loss for training models.
- Focal loss significantly outperforms cross-entropy and other baselines on calibration error scores (e.g. ECE) without compromising on test set accuracy.
- This improvement in focal loss is present both pre and post temperature scaling.
- We propose a sample-dependent adaptive way of deciding $\gamma$, the focal loss hyperparameter.
- Finally, we show that training on focal loss can be better than post-hoc calibration using temperature scaling, especially on out-of-distribution samples.
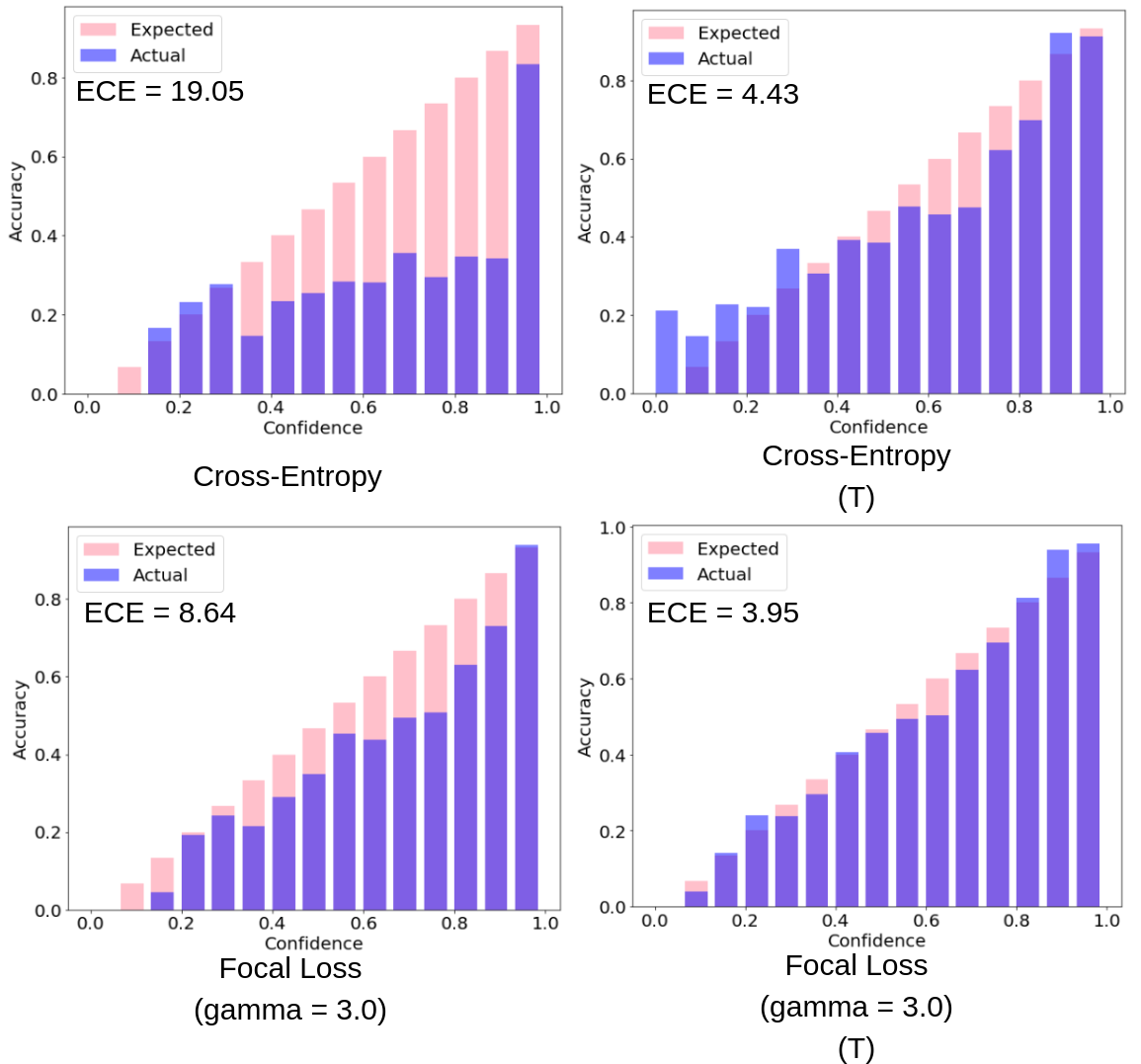 Fig. 1: Reliability diagrams for a ResNet110 trained on CIFAR-100
Fig. 1: Reliability diagrams for a ResNet110 trained on CIFAR-100
What Causes Miscalibration?
- We train a ResNet-50 on CIFAR-10 using cross-entropy loss for 350 epochs.
- The initial learning rate is 0.1 and it drops by a factor of 10 at epochs 150 and 250.
- We plot the NLL and entropy of the softmax distribution over the course of training for both correctly and incorrectly classified train and test samples.
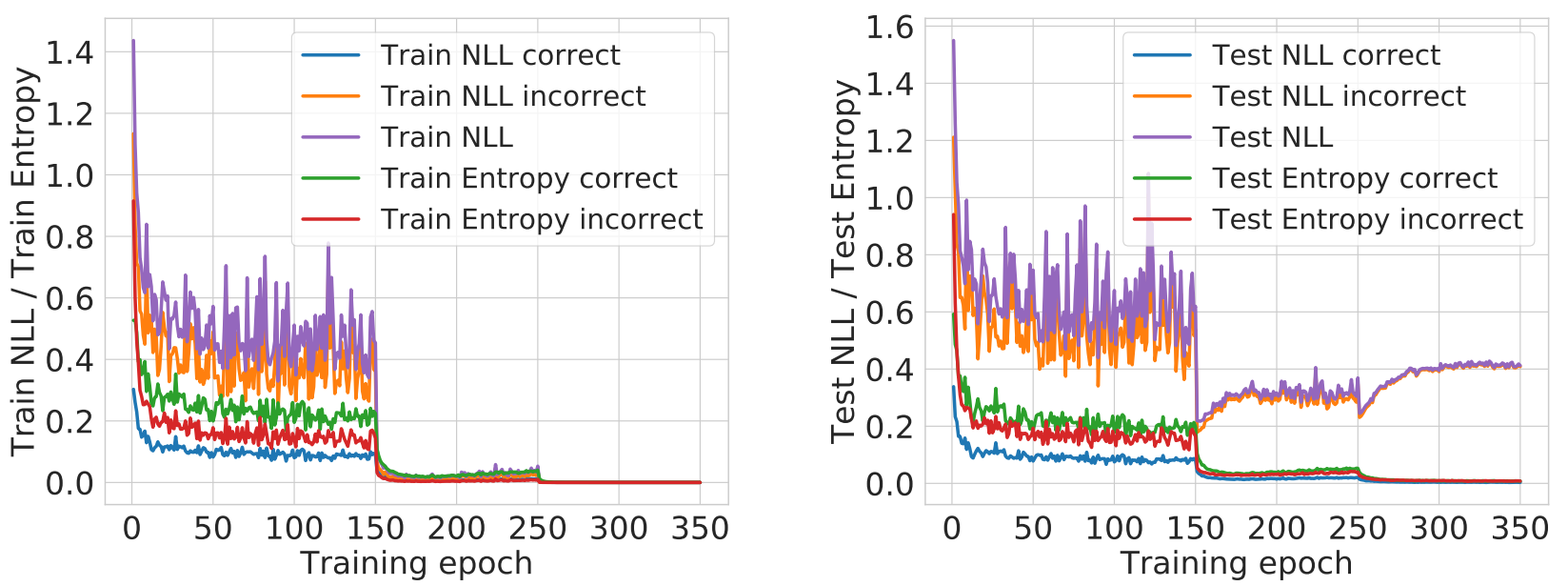 Fig. 2: NLL and softmax entropy computed over CIFAR-10 train and test sets (for correctly and incorrectly classified samples) over the course of training a ResNet-50 usign cross-entropy loss.
Fig. 2: NLL and softmax entropy computed over CIFAR-10 train and test sets (for correctly and incorrectly classified samples) over the course of training a ResNet-50 usign cross-entropy loss.
Two observations are worth noting from the above plots:
- Curse of misclassified samples: The NLL overfitting is quite apparent after training epoch 150. Also, the rise in test set NLL is only because of misclassified test samples.
- Peak at the wrong place: While the test set NLL rises, the test set entropy decreases throughout training even for misclassified samples. Hence, the model gets more and more confident on its predictions irrespective of their correctness.
We posit the reason behind the above observations as follows:
- Even after obtaining a 100% training accuracy, the optimiser can still reduce the loss further by increasing the model’s confidences on its predictions.
- In order to increase its confidence, the model increases the magnitudes of the logits which in turn is achieved by increasing the magnitudes of its weights.
Improving Calibration using Focal Loss
We explore an alternative loss function, focal loss. Below are the forms of the two loss functions, cross-entropy (CE) and focal loss (Focal) (assuming one-hot ground truth encodings):
$$\mathcal{L}_{\mathrm{CE}} = - \log p$$
$$\mathcal{L}_{\mathrm{Focal}} = -(1-p)^\gamma \log p$$
In the above equations $p$ is the probability assigned by the model to the ground-truth correct class. When compared with cross-entropy, focal loss has an added $(1-p)^\gamma$ factor. The idea behind this is to give more preference to samples for which the model is placing less probability mass on the correct class. $\gamma$ is a hyperparameter.
Why might focal loss improve calibration?
Focal Loss minimises a regularised KL divergence. We know that cross-entropy loss minimises the Kullback-Leibler (KL) divergence between the target distribution $q$ over classes and the predicted softmax distribution $\hat{p}$. As it turns out, focal loss minimises a regularised KL divergence between the target and predicted distributions as shown below.
$$\mathcal{L}_{\mathrm{Focal}} \geq \mathrm{KL}(q||\hat{p}) - \gamma \mathbb{H}[\hat{p}]$$
- The regulariser is the entropy of the predicted distribution and the regularisation coefficient is $\gamma$.
- Hence, focal loss tries to minimise the KL divergence between the predicted and target distributions while at the same time increasing the entropy of the predicted distribution.
- Note that in the case of one-hot target distributions, only the component of entropy corresponding to the ground-truth correct class (i.e., $\gamma(-p \log p)$) is maximised.
- This prevents the predicted softmax distributions from becoming too peaky (low entropy) and the model from becoming overconfident.
How does focal loss fare on NLL overfitting?
On the same training setup as above (i.e., ResNet-50 on CIFAR-10), if we use focal loss with $\gamma$ values set to 1, 2 and 3, the test set NLL vs training epochs plot is as follows.
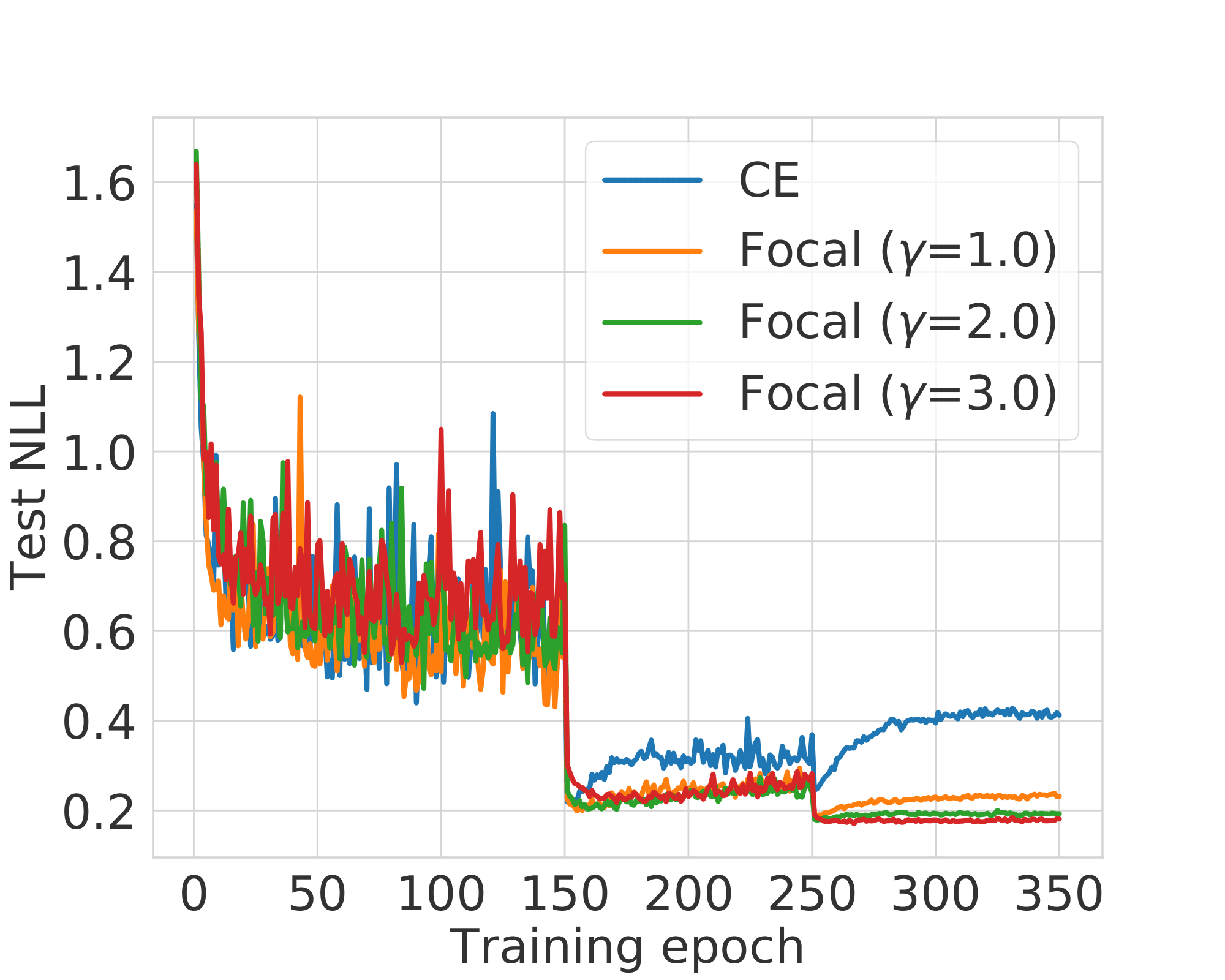 Fig. 3: Test set NLL computed over different training epochs for ResNet-50 models trained using cross-entropy and focal loss with $\gamma$ values 1,2 and 3.
Fig. 3: Test set NLL computed over different training epochs for ResNet-50 models trained using cross-entropy and focal loss with $\gamma$ values 1,2 and 3.
- NLL overfitting is significantly reduced for models trained using focal loss!
- There also seems to be an ordering to this betterment where focal loss with $\gamma=3$ outperforms focal loss with $\gamma=2$, which outperforms the one with $\gamma=1$.
Does focal loss regularise model weights?
If we consider the gradient of focal loss with respect to the last layer model weights $w$ and the same for cross-entropy, we find that for a single sample, the following relation exists.
$$\frac{\partial\mathcal{L}_{\mathrm{Focal}}}{\partial w} = \frac{\partial\mathcal{L}}{\partial w}g(p, \gamma)$$
The factor $g(p, \gamma)$ is a function of both the predicted correct class probability $p$ and $\gamma$. On plotting $g(p, \gamma)$ against $p$ for different values of $\gamma$, we get the following plot.
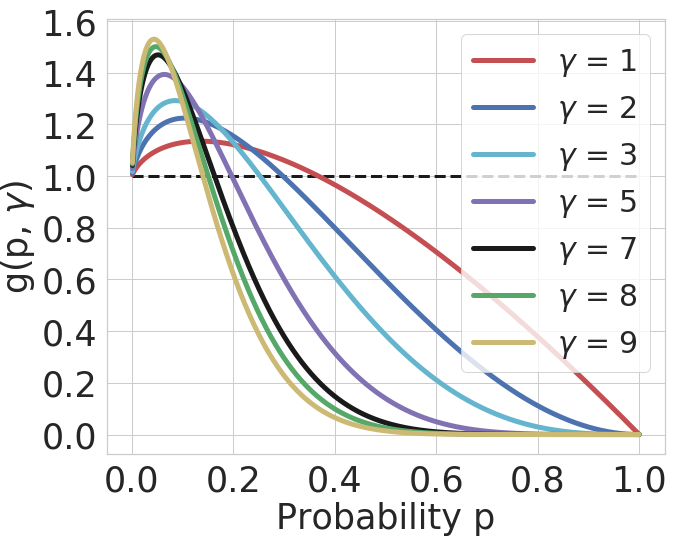 Fig. 4: $g(p, \gamma)$ vs $p$ plot.
Fig. 4: $g(p, \gamma)$ vs $p$ plot.
- We see a pattern here, that higher $\gamma$ leads to higher gradient in focal loss for low values of $p$ and dying gradients for higher $p$.
- We use this observation to adaptively select $\gamma$ sample wise such that the network can give more weight to samples with lower correct class probability. We call this training method as FLSD.
- For each value of $\gamma$, $g(p, \gamma) < 1$ when $p$ is above a certain threshold probability.
- This means that during training, once the network starts getting more confident on its predictions, the gradients for focal loss start having lower and lower norm as compared to the gradients for cross-entropy.
- Accordingly, the weight norms for focal loss should also reduce as compared to that of cross-entropy. To see this empirically, we plot the weight norms of the last linear layer for our training setup.
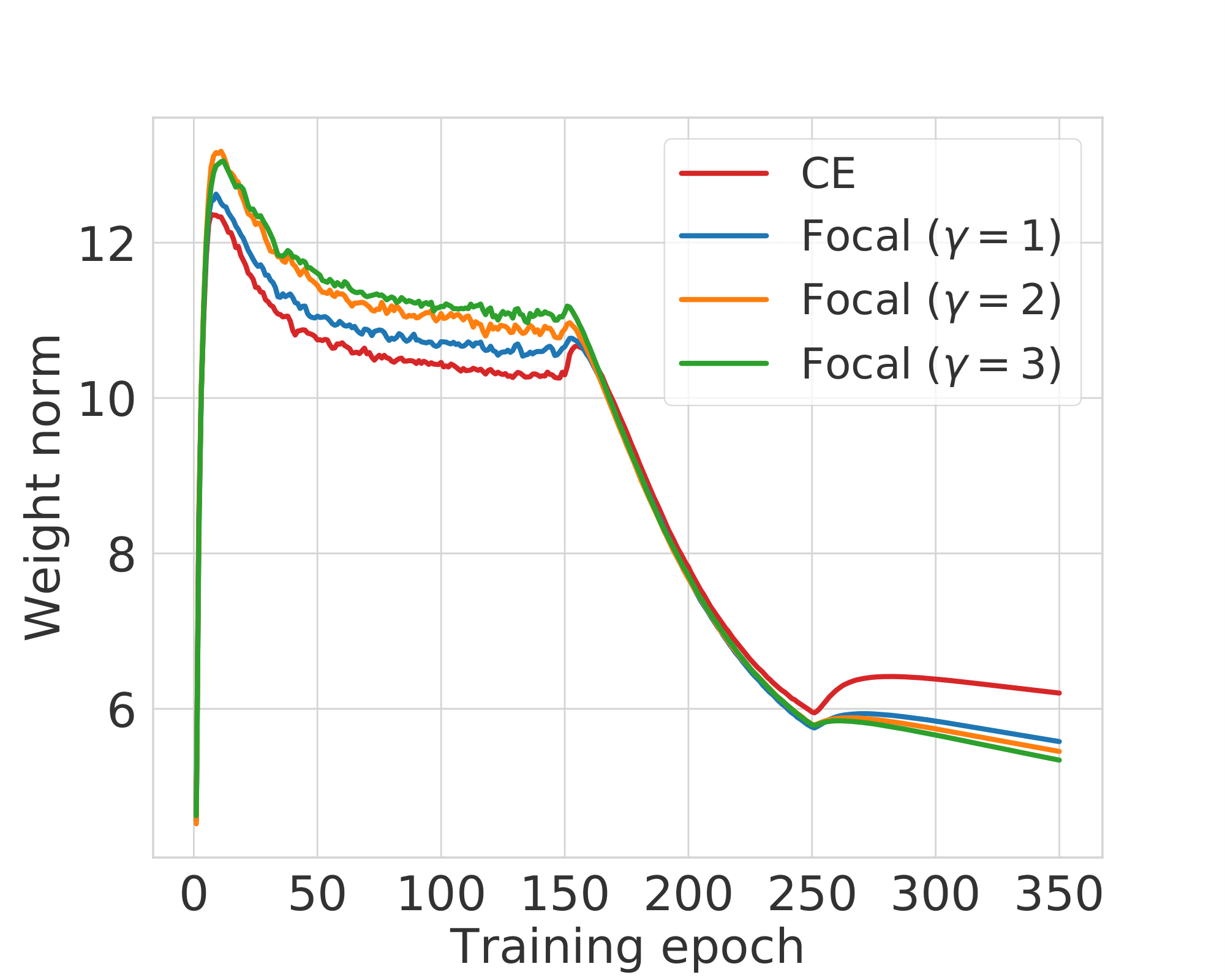 Fig. 5: Weight norm of the last linear layer over the course of training.
Fig. 5: Weight norm of the last linear layer over the course of training.
- For the first few training epochs, the focal loss weight norms are larger than cross-entropy.
- However, after epoch 150, the point from where the network starts getting miscalibrated, the ordering of weight norms completely reverses and focal loss has lower weight norms than cross-entropy.
This provides strong evidence in favour of our hypothesis that focal loss regularises weight norms in the network once the network achieves a certain level of confidence on its predictions.
Empirical Results
Classification Results (Calibration and Accuracy)
- We test the performance of focal loss on several datasets, architectures and using multiple different calibration error scores which include the Expected Calibration Error (ECE), Adaptive ECE (AdaECE), Classwise-ECE and others.
- We also compare with loss baselines other than cross-entropy, like Brier Score, MMCE and cross-entropy with label smoothing.
- We present error bars with confidence intervals for ECE, AdaECE and Classwise-ECE for ResNet-50 and ResNet-110 trained on CIFAR-10 as well as the test set classification error for the same models below.
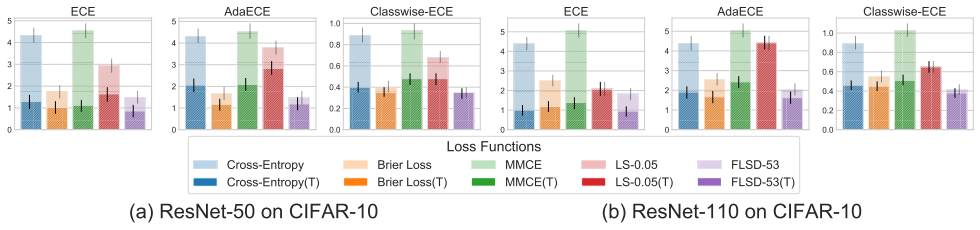 Fig. 6: Error bar plots with confidence intervals for ECE, AdaECE and Classwise-ECE computed for ResNet-50 (first 3 from the left) and ResNet-110 (first 3 from the right) on CIFAR-10. T: post-temperature scaling
Fig. 6: Error bar plots with confidence intervals for ECE, AdaECE and Classwise-ECE computed for ResNet-50 (first 3 from the left) and ResNet-110 (first 3 from the right) on CIFAR-10. T: post-temperature scaling
| Model Architecture | Cross-Entropy | Brier Loss | MMCE | LS-0.05 | FL-3 (Ours) | FLSD-53 (Ours) |
|---|---|---|---|---|---|---|
| ResNet-50 | 4.95 | 5.0 | 4.99 | 5.29 | 5.25 | 4.98 |
| ResNet-110 | 4.89 | 5.48 | 5.4 | 5.52 | 5.08 | 5.42 |
- Models trained using focal loss broadly outperform all other baselines on all the metrics both before and after temperature scaling!
- In quite a few cases, the difference in performance is statistically significant.
- Moreover, models trained on focal loss do not compromise on test set error or accuracy. All the models we train obtain test set classification errors in the same ballpark.
Detection of OOD Samples
We run the models trained using CIFAR-10 on test data drawn from the SVHN dataset which is out-of-distribution and consider the softmax entropy of these networks as a measure of uncertainty. For ResNet-110, the ROC plots obtained from this experiment are provided below.
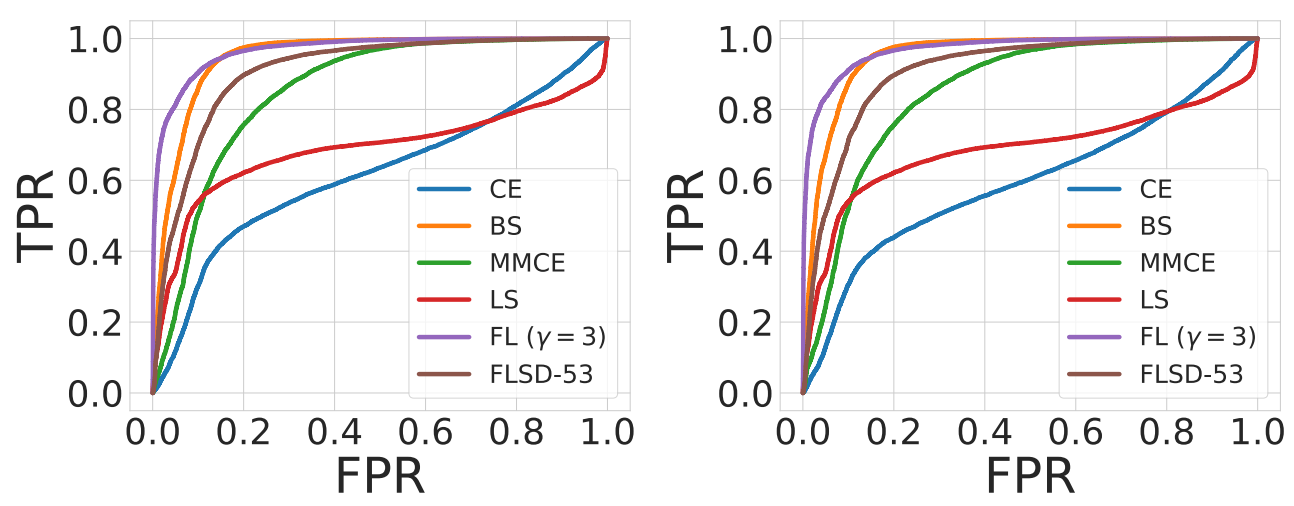 Fig. 7: ROC plots obtained from ResNet-110 trained on CIFAR-10 and tested on SVHN. Left: pre-temperature scaling, right: post-temperature scaling.
Fig. 7: ROC plots obtained from ResNet-110 trained on CIFAR-10 and tested on SVHN. Left: pre-temperature scaling, right: post-temperature scaling.
- The results indicate that models trained on focal loss, with higher AUROC, are able to detect out-of-distribution samples from SVHN much better than models trained on cross-entropy loss.
- What is particularly important to see here is that this improved performance is shown both pre and post temperature scaling!
Thus, focal loss seems to be a good alternative to the conventionally used cross-entropy loss for producing confident and calibrated models without compromising on classification accuracy. Our paper provides with a lot more experiments and analysis, please have a look. The code with all the pretrained models is also available.
Citation and Contact
If the code or the paper has been useful in your research, please add a citation to our work:
@article{mukhoti2020calibrating,
title={Calibrating Deep Neural Networks using Focal Loss},
author={Mukhoti, Jishnu and Kulharia, Viveka and Sanyal, Amartya and Golodetz, Stuart and Torr, Philip HS and Dokania, Puneet K},
booktitle={Advances in Neural Information Processing Systems},
year={2020}
}
For any questions related to this work, please feel free to reach out to us at jishnu.mukhoti@eng.ox.ac.uk or viveka@robots.ox.ac.uk.
Jishnu Mukhoti
AI Lead, Founding Team at Finster AI
My research interests include a variety of topics broadly covering methods to scale modern AI models in a safe and robust manner.